
Browse Source
merge from 1.1.0 upstream
 lidongdai
lidongdai
14 changed files with 139 additions and 42 deletions
+ 55
- 0
docs/zh_CN/1.1.0-release.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 0
docs/zh_CN/SUMMARY.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 1
docs/zh_CN/book.json
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
docs/zh_CN/images/hive_kerberos.png
{kind=link}
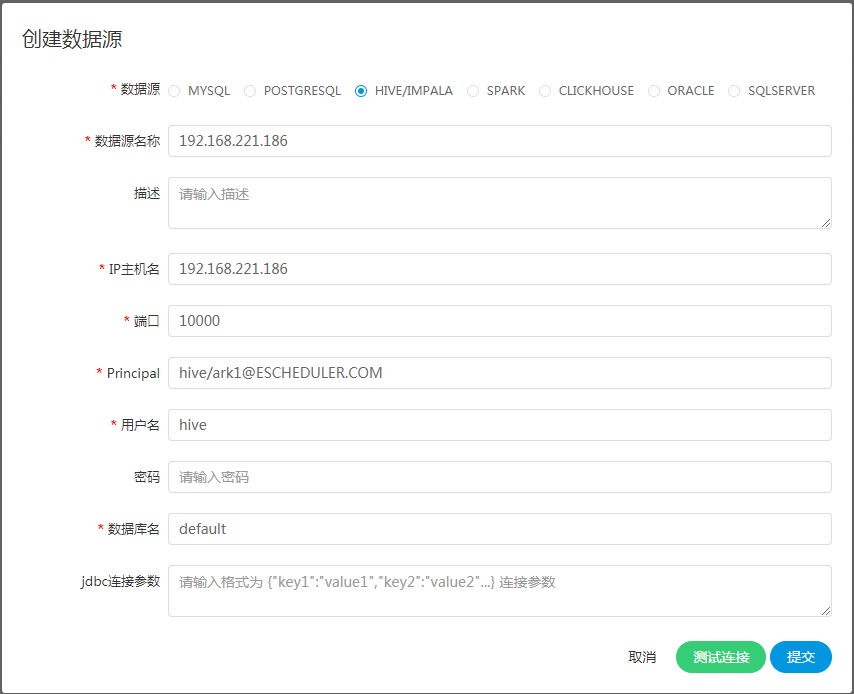
BIN
docs/zh_CN/images/sparksql_kerberos.png
{kind=link}

+ 38
- 22
docs/zh_CN/系统使用手册.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 0
escheduler-api/src/main/java/cn/escheduler/api/enums/Status.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 24
- 7
escheduler-api/src/main/java/cn/escheduler/api/service/ExecutorService.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 1
escheduler-api/src/main/java/cn/escheduler/api/service/ProcessDefinitionService.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 4
- 4
escheduler-api/src/main/java/cn/escheduler/api/service/SchedulerService.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 7
- 4
escheduler-common/src/main/java/cn/escheduler/common/queue/TaskQueueZkImpl.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 2
- 1
escheduler-server/src/main/java/cn/escheduler/server/utils/LoggerUtils.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 5
- 0
escheduler-server/src/main/java/cn/escheduler/server/worker/runner/FetchTaskThread.java
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 2
escheduler-ui/src/js/conf/home/pages/dag/_source/dag.vue
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||