|
|
@@ -60,7 +60,7 @@
|
|
|
### 执行流程定义
|
|
|
- **未上线状态的流程定义可以编辑,但是不可以运行**,所以先上线工作流
|
|
|
> 点击工作流定义,返回流程定义列表,点击”上线“图标,上线工作流定义。
|
|
|
-
|
|
|
+
|
|
|
> "下线"工作流之前,要先将定时管理的定时下线,才能成功下线工作流定义
|
|
|
|
|
|
- 点击”运行“,执行工作流。运行参数说明:
|
|
|
@@ -98,28 +98,28 @@
|
|
|
|
|
|
### 查看流程实例
|
|
|
> 点击“工作流实例”,查看流程实例列表。
|
|
|
-
|
|
|
+
|
|
|
> 点击工作流名称,查看任务执行状态。
|
|
|
-
|
|
|
+
|
|
|
<p align="center">
|
|
|
<img src="https://analysys.github.io/easyscheduler_docs_cn/images/instance-detail.png" width="60%" />
|
|
|
</p>
|
|
|
|
|
|
> 点击任务节点,点击“查看日志”,查看任务执行日志。
|
|
|
-
|
|
|
+
|
|
|
<p align="center">
|
|
|
<img src="https://analysys.github.io/easyscheduler_docs_cn/images/task-log.png" width="60%" />
|
|
|
</p>
|
|
|
-
|
|
|
+
|
|
|
> 点击任务实例节点,点击**查看历史**,可以查看该流程实例运行的该任务实例列表
|
|
|
-
|
|
|
+
|
|
|
<p align="center">
|
|
|
<img src="https://analysys.github.io/EasyScheduler/zh_CN/images/task_history.png" width="60%" />
|
|
|
</p>
|
|
|
|
|
|
|
|
|
> 对工作流实例的操作:
|
|
|
-
|
|
|
+
|
|
|
<p align="center">
|
|
|
<img src="https://analysys.github.io/easyscheduler_docs_cn/images/instance-list.png" width="60%" />
|
|
|
</p>
|
|
|
@@ -165,7 +165,7 @@
|
|
|
- 密码:设置连接MySQL的密码
|
|
|
- 数据库名:输入连接MySQL的数据库名称
|
|
|
- Jdbc连接参数:用于MySQL连接的参数设置,以JSON形式填写
|
|
|
-
|
|
|
+
|
|
|
<p align="center">
|
|
|
<img src="https://analysys.github.io/easyscheduler_docs_cn/images/mysql_edit.png" width="60%" />
|
|
|
</p>
|
|
|
@@ -191,7 +191,7 @@
|
|
|
#### 创建、编辑HIVE数据源
|
|
|
|
|
|
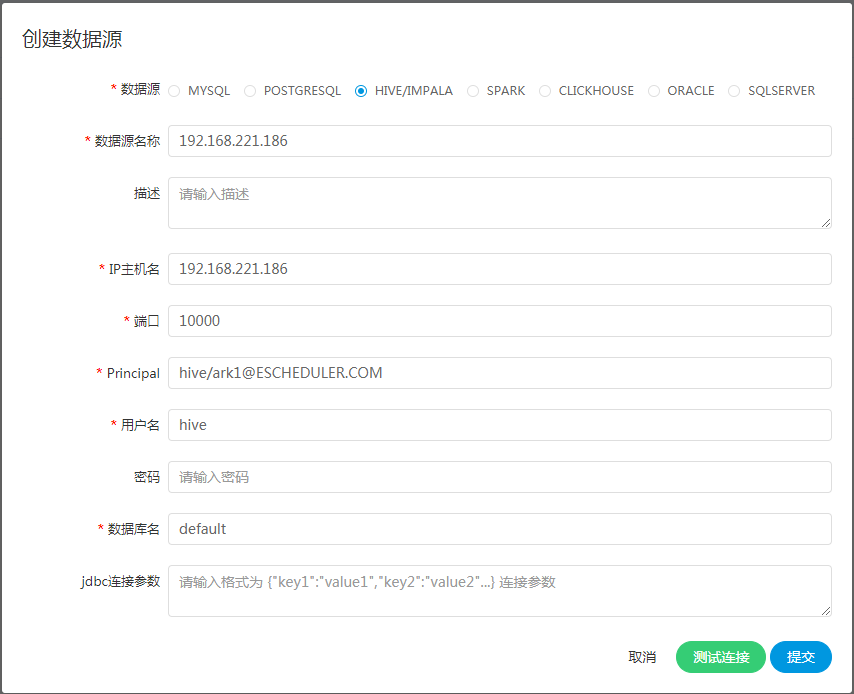
1.使用HiveServer2方式连接
|
|
|
-
|
|
|
+
|
|
|
<p align="center">
|
|
|
<img src="https://analysys.github.io/easyscheduler_docs_cn/images/hive_edit.png" width="60%" />
|
|
|
</p>
|
|
|
@@ -207,12 +207,19 @@
|
|
|
- Jdbc连接参数:用于HIVE连接的参数设置,以JSON形式填写
|
|
|
|
|
|
2.使用HiveServer2 HA Zookeeper方式连接
|
|
|
-
|
|
|
+
|
|
|
<p align="center">
|
|
|
<img src="https://analysys.github.io/easyscheduler_docs_cn/images/hive_edit2.png" width="60%" />
|
|
|
</p>
|
|
|
|
|
|
|
|
|
+注意:如果开启了**kerberos**,则需要填写 **Principal**
|
|
|
+<p align="center">
|
|
|
+ <img src="https://analysys.github.io/easyscheduler_docs_cn/images/hive_edit2.png" width="60%" />
|
|
|
+ </p>
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
#### 创建、编辑Spark数据源
|
|
|
|
|
|
<p align="center">
|
|
|
@@ -231,7 +238,7 @@
|
|
|
|
|
|
### 上传资源
|
|
|
- 上传资源文件和udf函数,所有上传的文件和资源都会被存储到hdfs上,所以需要以下配置项:
|
|
|
-
|
|
|
+
|
|
|
```
|
|
|
conf/common/common.properties
|
|
|
-- hdfs.startup.state=true
|
|
|
@@ -242,7 +249,7 @@ conf/common/hadoop.properties
|
|
|
```
|
|
|
|
|
|
#### 文件管理
|
|
|
-
|
|
|
+
|
|
|
> 是对各种资源文件的管理,包括创建基本的txt/log/sh/conf等文件、上传jar包等各种类型文件,以及编辑、下载、删除等操作。
|
|
|
<p align="center">
|
|
|
<img src="https://analysys.github.io/easyscheduler_docs_cn/images/file-manage.png" width="60%" />
|
|
|
@@ -287,7 +294,7 @@ conf/common/hadoop.properties
|
|
|
|
|
|
#### 资源管理
|
|
|
> 资源管理和文件管理功能类似,不同之处是资源管理是上传的UDF函数,文件管理上传的是用户程序,脚本及配置文件
|
|
|
-
|
|
|
+
|
|
|
* 上传udf资源
|
|
|
> 和上传文件相同。
|
|
|
|
|
|
@@ -303,7 +310,7 @@ conf/common/hadoop.properties
|
|
|
- 参数:用来标注函数的输入参数
|
|
|
- 数据库名:预留字段,用于创建永久UDF函数
|
|
|
- UDF资源:设置创建的UDF对应的资源文件
|
|
|
-
|
|
|
+
|
|
|
<p align="center">
|
|
|
<img src="https://analysys.github.io/easyscheduler_docs_cn/images/udf_edit.png" width="60%" />
|
|
|
</p>
|
|
|
@@ -312,7 +319,7 @@ conf/common/hadoop.properties
|
|
|
|
|
|
- 安全中心是只有管理员账户才有权限的功能,有队列管理、租户管理、用户管理、告警组管理、worker分组、令牌管理等功能,还可以对资源、数据源、项目等授权
|
|
|
- 管理员登录,默认用户名密码:admin/escheduler123
|
|
|
-
|
|
|
+
|
|
|
### 创建队列
|
|
|
- 队列是在执行spark、mapreduce等程序,需要用到“队列”参数时使用的。
|
|
|
- “安全中心”->“队列管理”->“创建队列”
|
|
|
@@ -357,7 +364,7 @@ conf/common/hadoop.properties
|
|
|
### 令牌管理
|
|
|
- 由于后端接口有登录检查,令牌管理,提供了一种可以通过调用接口的方式对系统进行各种操作。
|
|
|
- 调用示例:
|
|
|
-
|
|
|
+
|
|
|
```令牌调用示例
|
|
|
/**
|
|
|
* test token
|
|
|
@@ -477,15 +484,15 @@ conf/common/hadoop.properties
|
|
|
|
|
|
### 依赖(DEPENDENT)节点
|
|
|
- 依赖节点,就是**依赖检查节点**。比如A流程依赖昨天的B流程执行成功,依赖节点会去检查B流程在昨天是否有执行成功的实例。
|
|
|
-
|
|
|
+
|
|
|
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
|
|
|
|
|
|
<p align="center">
|
|
|
<img src="https://analysys.github.io/easyscheduler_docs_cn/images/dependent_edit.png" width="60%" />
|
|
|
</p>
|
|
|
-
|
|
|
+
|
|
|
> 依赖节点提供了逻辑判断功能,比如检查昨天的B流程是否成功,或者C流程是否执行成功。
|
|
|
-
|
|
|
+
|
|
|
<p align="center">
|
|
|
<img src="https://analysys.github.io/easyscheduler_docs_cn/images/depend-node.png" width="80%" />
|
|
|
</p>
|
|
|
@@ -536,7 +543,7 @@ conf/common/hadoop.properties
|
|
|
|
|
|
### SPARK节点
|
|
|
- 通过SPARK节点,可以直接直接执行SPARK程序,对于spark节点,worker会使用`spark-submit`方式提交任务
|
|
|
-
|
|
|
+
|
|
|
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
|
|
|
|
|
|
<p align="center">
|
|
|
@@ -563,7 +570,7 @@ conf/common/hadoop.properties
|
|
|
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
|
|
|
|
|
|
1. JAVA程序
|
|
|
-
|
|
|
+
|
|
|
<p align="center">
|
|
|
<img src="https://analysys.github.io/easyscheduler_docs_cn/images/mr_java.png" width="60%" />
|
|
|
</p>
|
|
|
@@ -592,7 +599,7 @@ conf/common/hadoop.properties
|
|
|
|
|
|
### Python节点
|
|
|
- 使用python节点,可以直接执行python脚本,对于python节点,worker会使用`python **`方式提交任务。
|
|
|
-
|
|
|
+
|
|
|
|
|
|
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
|
|
|
|

 qiaozhanwei
qiaozhanwei
{kind=link}
{kind=link}
